Key Takeaways
AlDBaran’s performance, as demonstrated in the previous installment of this series, can be improved beyond the baseline 48M updates per second. To obtain our previous results 24M and 48M updates per second, we further explore the following tunable parameters:
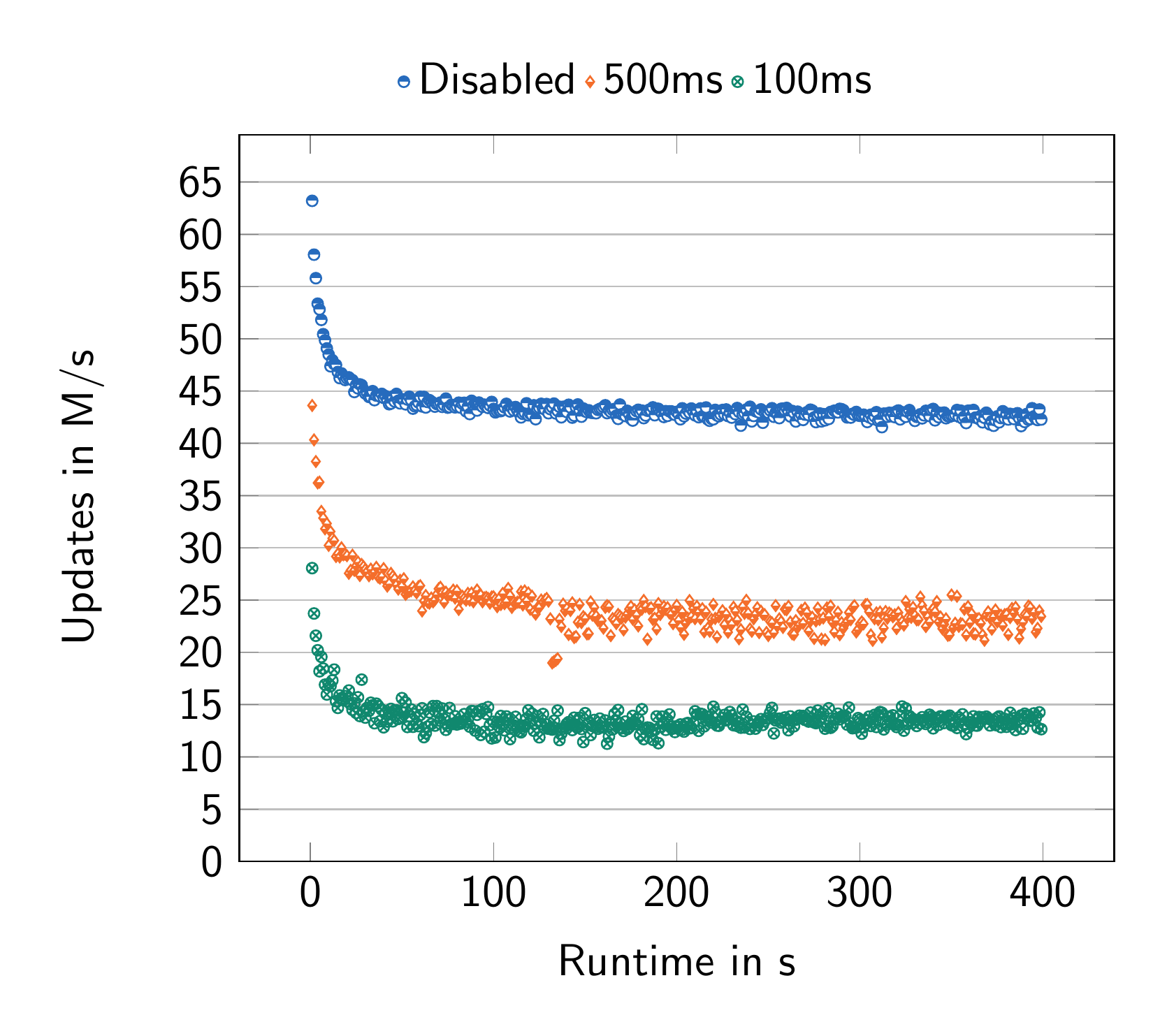
- By adjusting the snapshot period we can improve the performance by a factor of 2x. We observe an additional 2× boost when snapshots are disabled (24M → 48M updates per second).
- By tuning subtree root count we span a 37% throughput range; our previous 48M result sits near the midpoint.
To push the boundaries, the following new optimizations can also be used:
- Using a deterministic allocator gives another 25% in the lab.
- Using 2MB pages makes performance more predictable and gives another 5-10% more throughput.
In our previous post, we demonstrated AlDBaran achieving a sustained throughput of 48M state updates per second, a 20-30x improvement over existing solutions. This was achieved by means of clever engineering and fine-tuning a few of the configurable parameters. This article examines the design of AlDBaran, analyzing each layer to elucidate the critical optimizations—snapshot frequency, subtree root number, and memory prefetching—that collectively facilitate line-speed performance.
In the main workload, the two systems: Hyades and Pleiades periodically and asynchronously communicate with each other. The frequency of such communication, particularly the frequency with which the snapshot of the historical state is taken and committed to disk thus plays a vital role for the performance of the data store as a whole.
And one of the key insights was that this communication is highly dependent on the workload. There are use-cases such as operating a light client, where snapshots don’t even need to be taken. The block production also defines a natural cadence for taking state snapshots and committing that data to Hyades. And as we shall demonstrate below, the less frequently we take snapshots, the higher AlDBaran’s throughput.
Indeed, in part 1 the two headlining numbers: 24 M and 48 M updates per second were obtained with the snapshot period set to 500ms, and fully disabled, respectively. To obtain these numbers we needed to leverage the existing tunable parameters: e.g. the number of sub-tree roots, to a significant extent. Even then, we suspect that one can optimize the parameters further, for example, the number of subtree roots as well as snapshot frequency could be adjusted to better fit each other.
Consider the frequency with which state snapshots are accessed. Different kinds of state have drastically different latency tolerance. For example, an inclusion proof for a high-frequency trading system requires a higher frequency (pun intended) of snapshots.
As AlDBaran’s performance is quite sensitive to these decisions, there ought to be a discussion of the implications. In the following sections we provide some explanations of the tunable parameters.
.png)
AlDBaran's core architectural principle is the decoupling of the hot-path state computation from archival storage. The performance tuning, therefore, centers on managing the boundary between these two systems. In the following sections we shall explore the three most significant parameters governing the performance: frequency of snapshots in Hyades, the granularity of in-memory hashing in Pleiades, and deterministic allocation.
Effects of Snapshot Frequency
When first designing AlDBaran it was apparent that the historical state shall be the major bottleneck. It was also evident that only a subset of the operations required the historical data. This motivated our separation of the historical data store – Hyades, and the in-memory data store – Pleiades. This would allow workloads that need an as-fast-as-possible state commitment (re)computation to operate without the overhead of interacting with (typically slower) persistent storage.
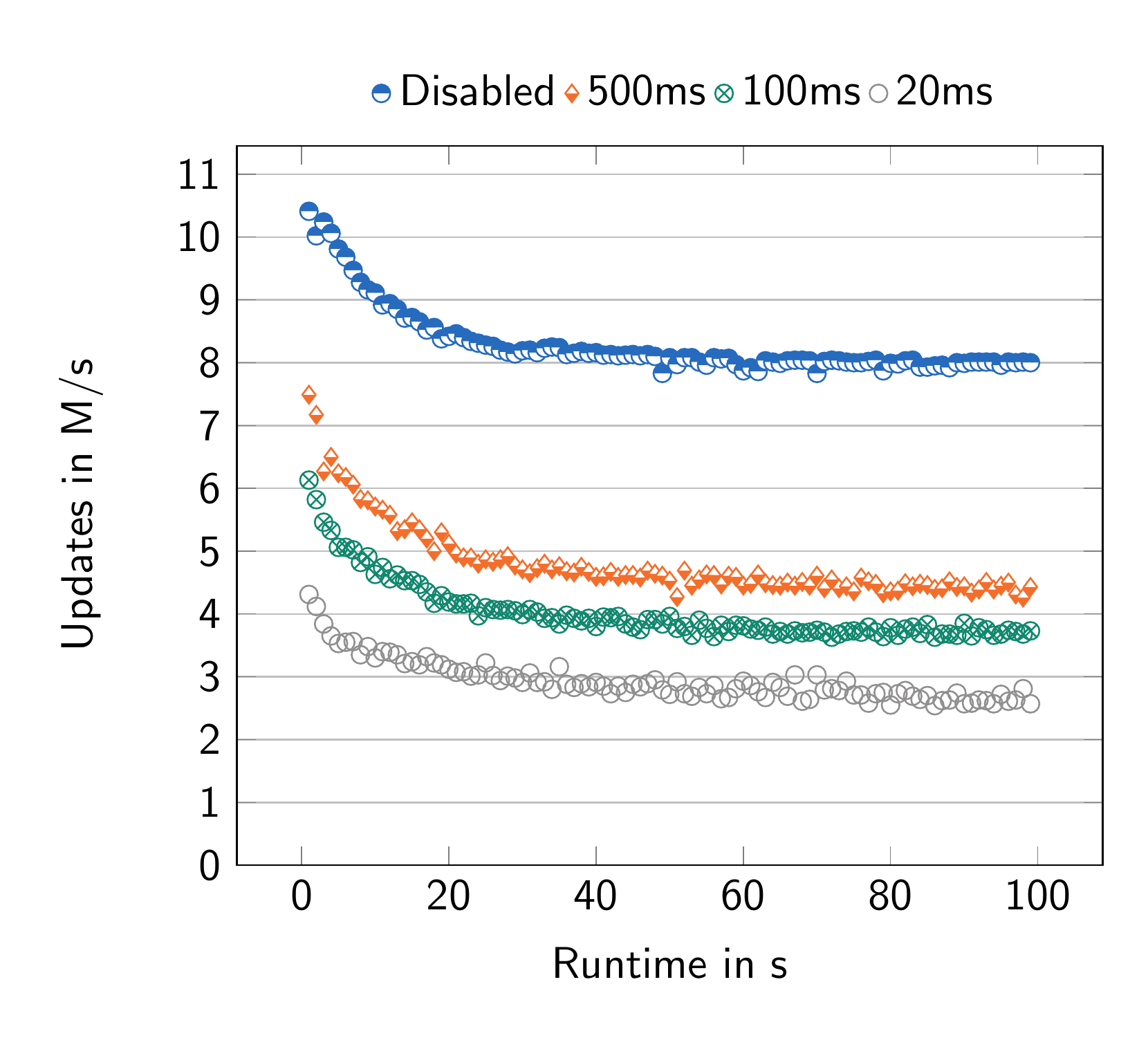
Figure 2 demonstrates the direct impact of snapshot period on overall system throughput. For ease of reproduction, measurements were additionally conducted on an Apple M4 Pro machine (Figure 2b), obviating the need for server deployment on AWS. Throughput reaches its maximum at 8 million updates per second with snapshots disabled. A 500ms snapshot period reduces throughput by a factor of two, consistent with the observed decrease from 48 million to 24 million updates per second on the 96-core AWS machine (Figure 2a).
This design allows the protocol to retain flexibility. For example, machines that cannot keep up with the chain at the 400ms cadence, could keep up with the chain at the 800ms cadence, or at another integer multiple of 400ms. These nodes can still produce useful work, the snapshots produced at the 800ms mark should be identical across the slowest nodes.
Varying the Number of Subtrees
Inspired by other authenticated stores, AlDBaran avoids re-hashing the Merkle tree all the way to the main root after every state update. Instead, we compute hash changes in parallel, in per-thread subtrees. This means that we only compute the top levels of the tree once per block. Since nodes closer to the root change more frequently, this dramatically reduces redundant hashing work.
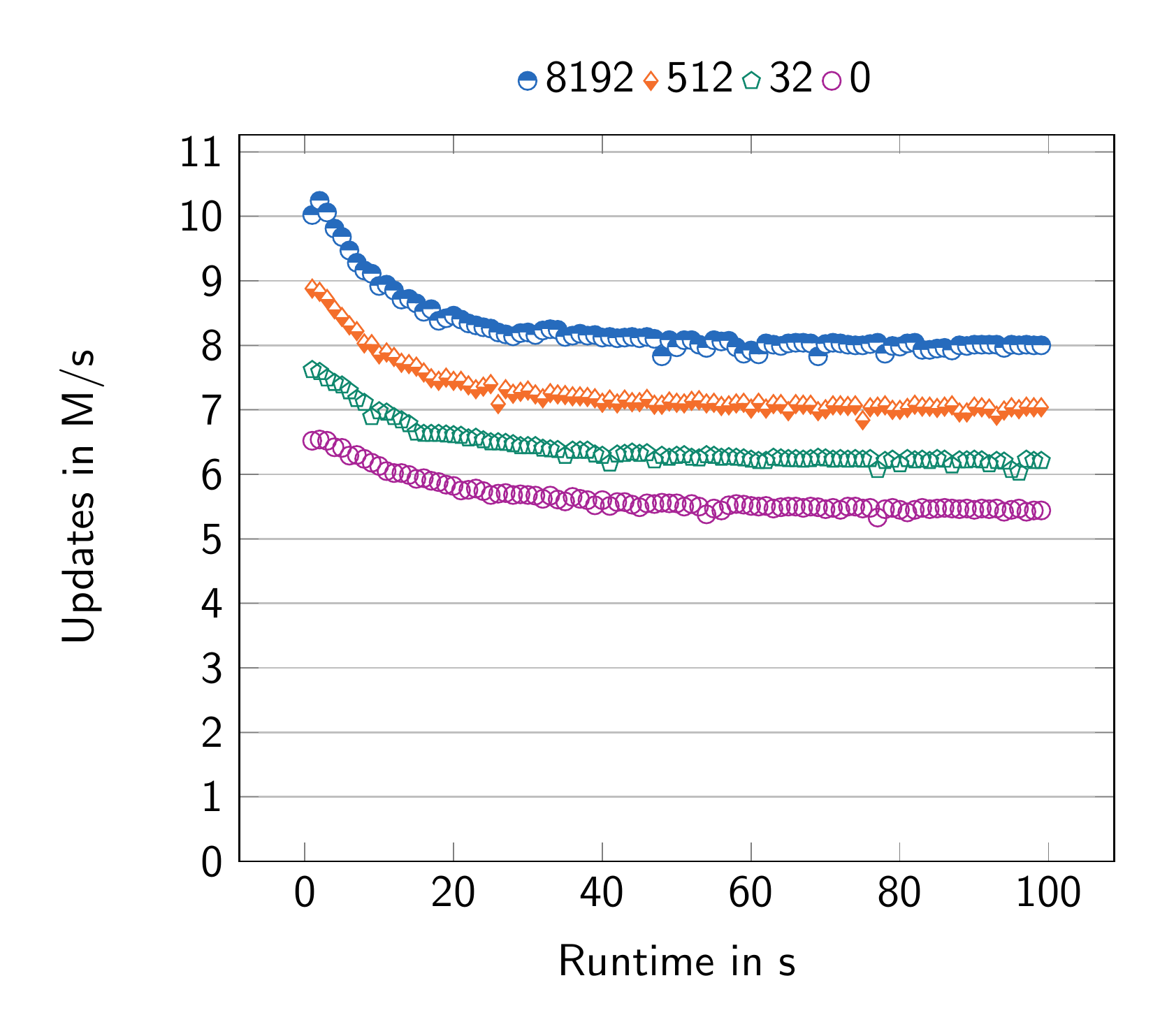
Figure 3 demonstrates this principle. Increasing the number of twig roots reduces the pressure on Pleiades, the in-memory component. The optimal number of twig roots is determined by a few key factors. The latency budget determines the upper bound on the amount of twig roots.
Thus finding the right number of subtree roots should be viewed as a multi-dimensional optimization problem. It is determined by a combination of parameters, such as the snapshot frequency, the topology of the authenticated data store, the latency budget, and the ratio of CPU core count and single-threaded performance.
In our tests (Figure 3) we observe a notable 37% difference in throughput based solely on adjusting the number of subtrees. Our previous measurements can be found in Part 1.
Prefetching
In its current iteration, AlDBaran is a purely CPU-based authenticated data store. Consequently, its performance is constrained by the inherent limitations of modern CPU architectures. Specifically, when data is not readily available in the local cache, the cache is “thrashed”, i.e. the CPU is not fed data optimally, and data loaded into the CPU caches has to be loaded from the comparatively slower DRAM.
Given these constraints, understanding the data processing timeline significantly boosts CPU efficiency. Our central data structure, a Merkle Tree, is designed to pre-determine which nodes require traversal. This foresight is crucial, considering the Pleiades' potential to house billions of nodes. To this end, AlDBaran employs a deterministic, breadth-first allocation order for nodes. This is then followed up by issuing explicit prefetch instructions, which on some architectures (e.g. Zen 4) is disabled for security.
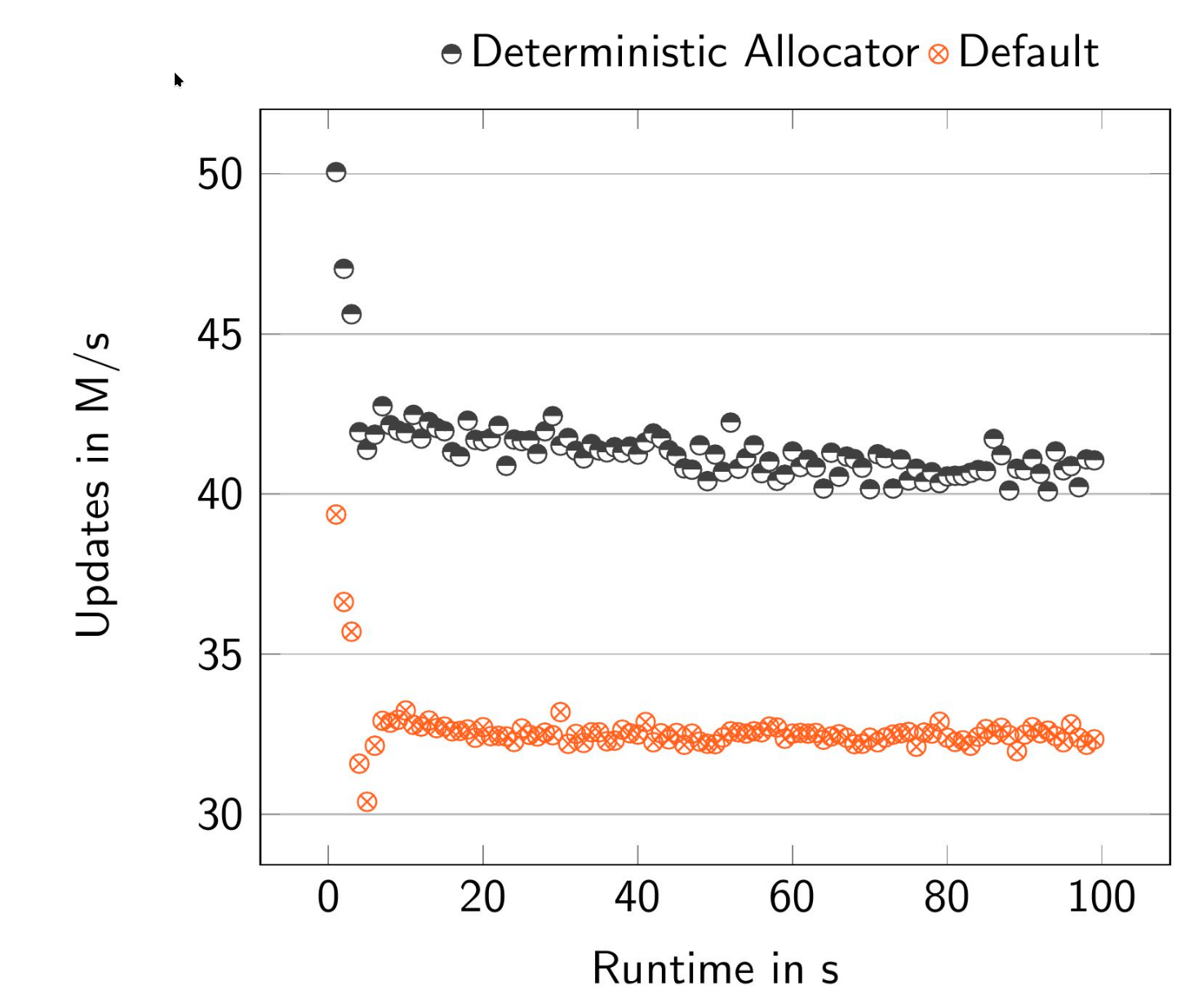
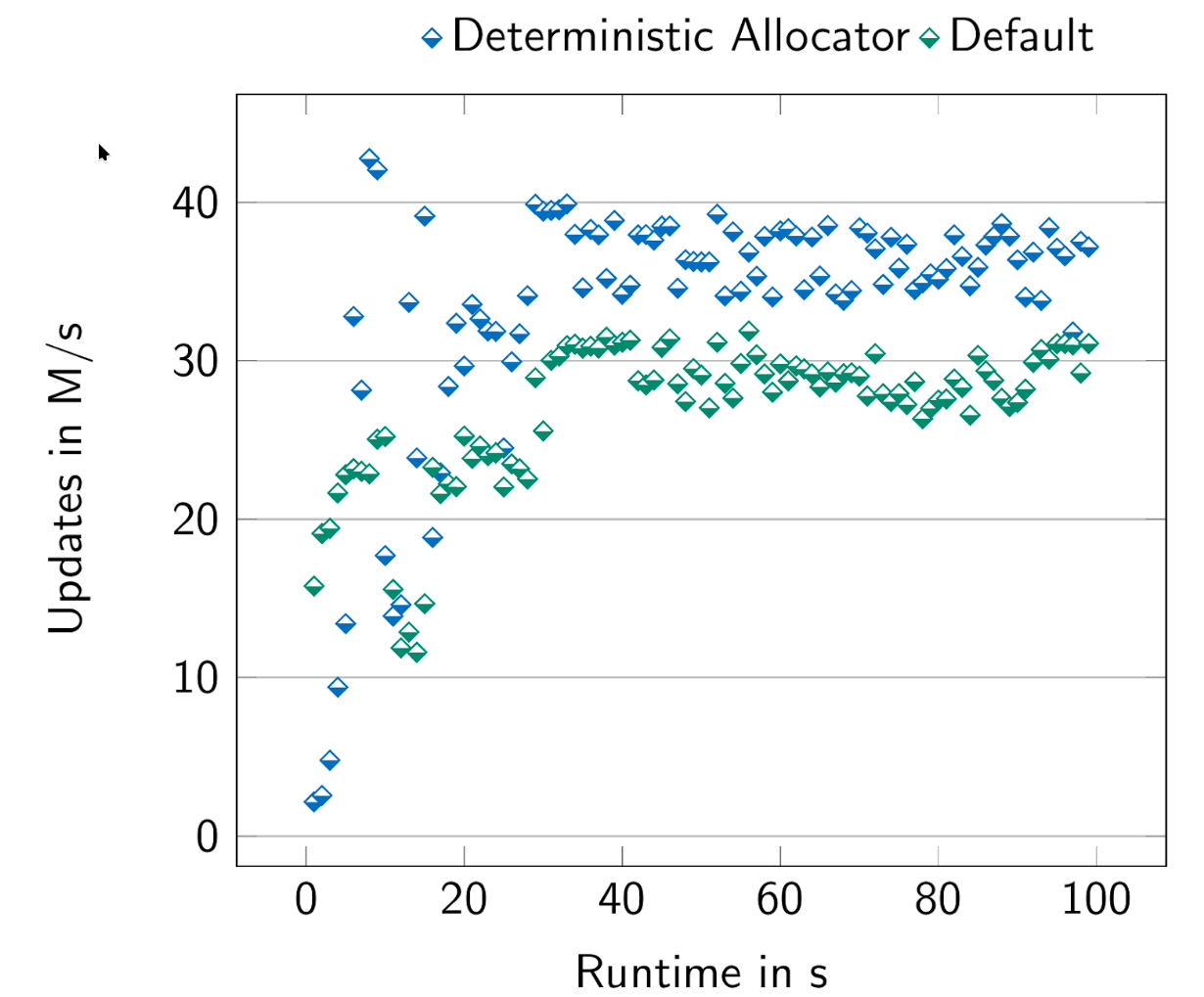
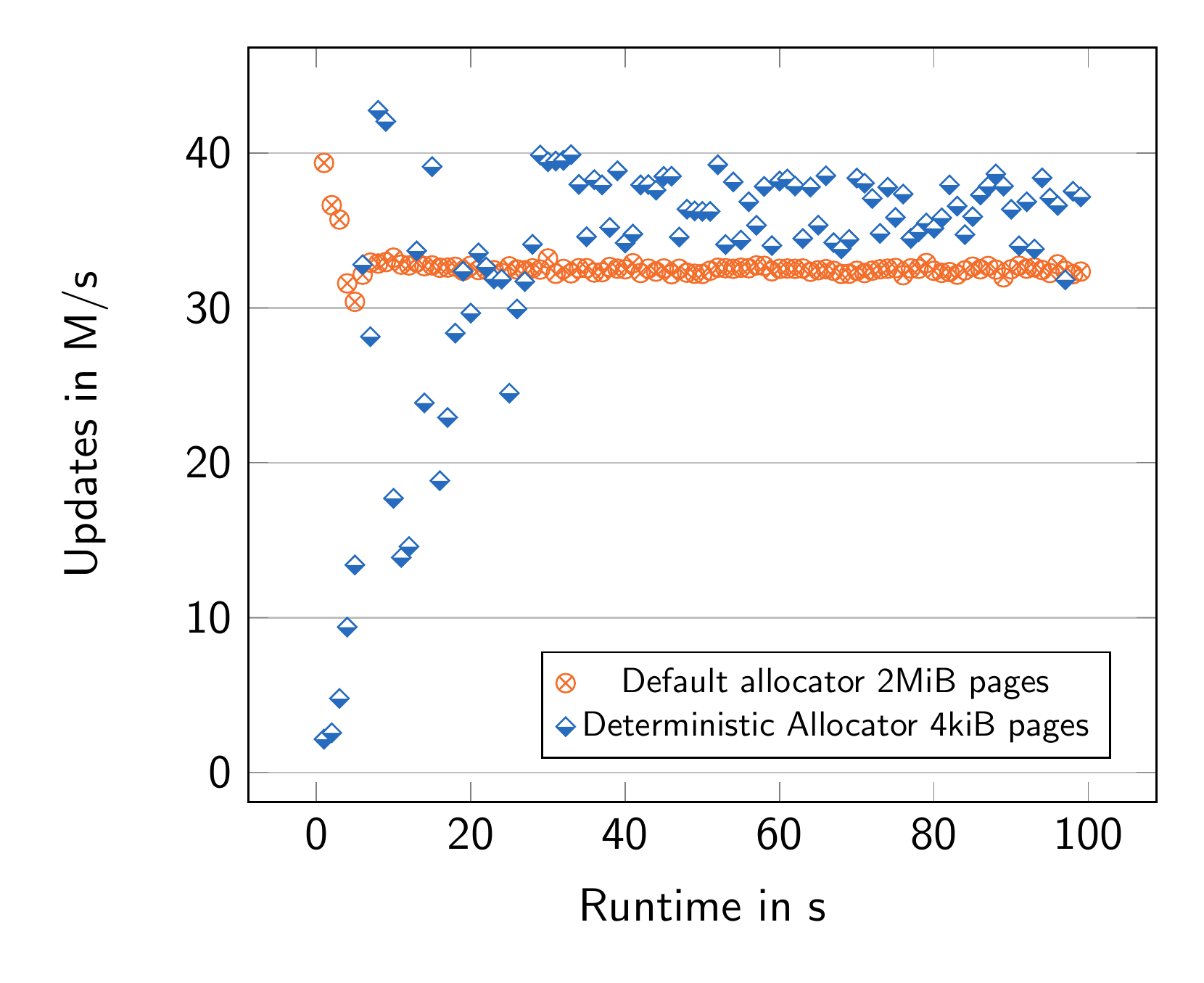
Figure 4 demonstrates the effects of enabling the prefetching (via deterministic allocation) on the overall performance of AlDBaran. The effect is most easily seen when the allocation takes place in 2MiB pages (Figure 4a). We observed a 25% increase in throughput given the deterministic allocation. The same effect can be observed on Figure 4b, where due to TLB walks, the data points are less concentrated, but the averages are still approximately 20% apart. It should be noted that enabling larger pages improves performance overall, but to a significantly lesser extent (as seen in Figure 4c).
It is also important to note that while optimizations like deterministic allocation for memory prefetching show significant gains (up to 25%) , the underlying prefetch instruction features may be disabled on common cloud platforms for security reasons. For example, our main cloud provider OVH disabled this on our original AMD Zen 4 testbench. AWS, thankfully, allows deterministic allocation to take place on our Intel Sapphire Rapids test machine, as that specific architecture is not vulnerable in the same way as Zen 4. This achieved 48M updates per second. Therefore, deploying AlDBaran in a production environment requires a careful assessment of the available hardware and software stack to maximize performance.
Conclusions
Our experiments reveal that optimizing snapshot frequency, enabling prefetching, and carefully managing the number of twig roots are crucial for maximizing AlDBaran's performance.
Tuning snapshot to 500ms gives 2x over baseline state updates per second; disabling yields another 2x. Proper subtree root depth spans a 37% throughput window, constrained by snapshot frequency. Enabling deterministic allocation adds 25%, 2 MB pages add 5–10%.
AlDBaran is designed to meet the needs of Eclipse, but its emergent flexibility suggests its applicability in other contexts.
Going forward we will explore AlDBaran in contexts like light nodes and trusted RPCs. We shall highlight deployment-time concerns such data-center based desegregated storage options.