Designing RPCs that can ingest and restitute data at the throughput enabled by the Eclipse GSVM client is a challenge in and of itself. One area of interest for Eclipse is how to enable trusted access to on-chain data, including light clients on top of an architecture based on Solana. After all, today, if you do not run your own node, you are essentially trusting a third party to provide the data truthfully, essentially defaulting back to a web2 trust model instead of the integrity guarantees expected of web3.
While authenticated databases provide the basis needed to generate proofs of authenticity for any on-chain account, properly versioning these proofs can lead to high storage costs for RPC providers. Many chains that rely on Merkle Patricia Tree (MPT) for data authentication typically store multiple versions of all the intermediate nodes of the tree, leading to significant storage and network overheads.
In this post, we explore how innovative storage solutions like COLE (Column-based Learned Storage) can help.
The Critical Role of Data Access in Blockchain Speed
A blockchain that can process a million TPS (transactions per second), but needs half a second to answer getAccount behaves, from the standpoint of the end-user, like a one-TPS chain. Real-time dashboards, DeFi arbitrage, DePin, on-chain games, and liquid money markets live or die on sub-second reads.
If that path stalls or bloats, the consequences are severe: developers are forced to build ad-hoc ETL stacks, node operators hemorrhage disk space, and the ecosystem loses the very speed advantage the SVM was designed to deliver. That is why Data Storage, alongside sequencing or execution, is a first-class pillar of Eclipse R&D.
Why Eclipse’s Storage Problem Is Different
Eclipse’s architecture (parallel SVM + Celestia DA + Ethereum settlement) puts four unique pressures on any fast RPC store.
Key Storage Pressures for Eclipse and why they matter
- Write torrent – A hot AMM pool can be updated hundreds of times in one slot, making storage bandwidth (not CPU) the bottleneck. The store must ingest that fire-hose without write stalls.
- Storage-bloat risk – Merkle trees or row stores duplicate path nodes; at multi-million TPS scale, disk costs balloon and threaten node economics.
- Simple but absolute rollbacks – A rare L1 re-org or fraud-proof can invalidate the tip. The store must drop orphaned slots instantly—no complex fork choice, no long re-sync.
- Sub-ms read SLA – Wallets, DeFi, DePin, and games still expect getAccount in < 1 ms, even when history spans petabytes.
Therefore, we need a data layout approach that soaks up bursty writes, grows sub-linearly, reverts with a metadata flip, and still delivers micro-second reads. In the next section, we show why a COLE-inspired, column-oriented design, augmented for Eclipse’s rollback model—hits those marks.
COLE at a Glance


COLE is a project presented at the 2024 FAST conference. It’s borne out of the desire to minimize wasted storage in an environment where historical MPT data is being stored. Here is the 30-second COLE primer:
- Column layout – stores every historical value for a given account contiguously, eliminating MPT path duplication.
- Learned index – a small ML based piece-wise-linear model predicts the exact byte offset of any (address, slot) key, slashing read IO.
- Merkle proofs – each immutable “run” carries its own Merkle tree, so inclusion proofs fall out of the storage format.
- Multiple builds – a synchronous reference engine (cole-index), an asynchronous merge variant for higher write throughput (cole-star), and a non-learned baseline (non-learn-cmi).
- Benchmark harness – the authors of COLE ship a full evaluation framework, giving us some hard numbers on space savings, tail latency, and throughput.
"Column-oriented" here refers to the way data is organized within each run (storage unit). Rather than storing complete records together (row-oriented), COLE separates different components of the data into distinct "columns". It means updates to a single address touch only the tiny slices of disk that belong to that address’ columns, not full rows and certainly not the entire trie path leading to them. That’s the core reason the COLE layout shrinks storage and keeps reads in the sub-millisecond range even when the same on-chain address is hammered thousands of times per second.
COLE -Concepts Explained
Run – the immutable data file
A run is the basic on-disk unit in COLE’s LSM-tree.
When the in-memory buffer fills, its (addr, slot, value…) rows are flushed once into a sorted, immutable bundle:
- state (.s) – the column-oriented key-value pairs
- model (.m) – the learned piece-wise-linear index for that run
- merkle (.h) – a Merkle tree over the rows, used for inclusion proofs
Because a run never changes after it is written, all further writes go to newer runs.
Level – a tier that groups runs of similar size
Runs are organised into size-graded levels (Level 0, Level 1, Level 2, …), just like in a classic Log-Structured-Merge tree:
- L0 — smallest, newest runs; Many small flushes arrive here.
- L1 … Ln — progressively larger (e.g., ×10 per level); Background compaction merges overlapping runs from the level above into a single, bigger run in the next level down.
Compaction keeps the number of runs per level bounded and guarantees that, at query time, COLE usually needs to probe only the newest run(s) before it finds the latest version of any key.
So, in short:
- Run = one immutable, sorted, column-formatted slice of state + its index & Merkle file.
- Level = a tier that holds runs of roughly the same size and manages their compaction schedule.
- Build = a full, runnable storage engine configuration that plugs a specific compaction strategy and index type into the shared column-run framework.
For a more detailed discussion on COLE, we recommend the reader to refer to the paper, the slides, the codebase, and the talk.
These features form a great foundation for the Eclipse storage blueprint, as explained below.
Design Pillars - A COLE-Inspired Storage Blueprint
To meet the four challenges outlined in the table above, we borrow some key ideas from the COLE (Column-based Learned Storage for Blockchain Systems) research prototype, then adapt them to Eclipse’s simpler rollback model. This results in a storage engine that can ingest a firehose, stay slim on disk, revert instantly, and respond to point reads (e.g. single-key look-ups like getAccount) in microseconds. Each pillar below addresses one or more of those demands.
Column Runs: History Packed Contiguously

Instead of scattering every state change across a Merkle-Trie path, we could write all versions of a single account back-to-back in an immutable “run” on disk. This approach is crucial for amortizing writes, as it consolidates multiple changes to a hot account into a single, highly efficient sequential write operation, rather than numerous costly random updates.
- Why it matters: Hot keys become an append-only log, so even a thousand rewrites in one block cost a single sequential write, not a thousand random updates.
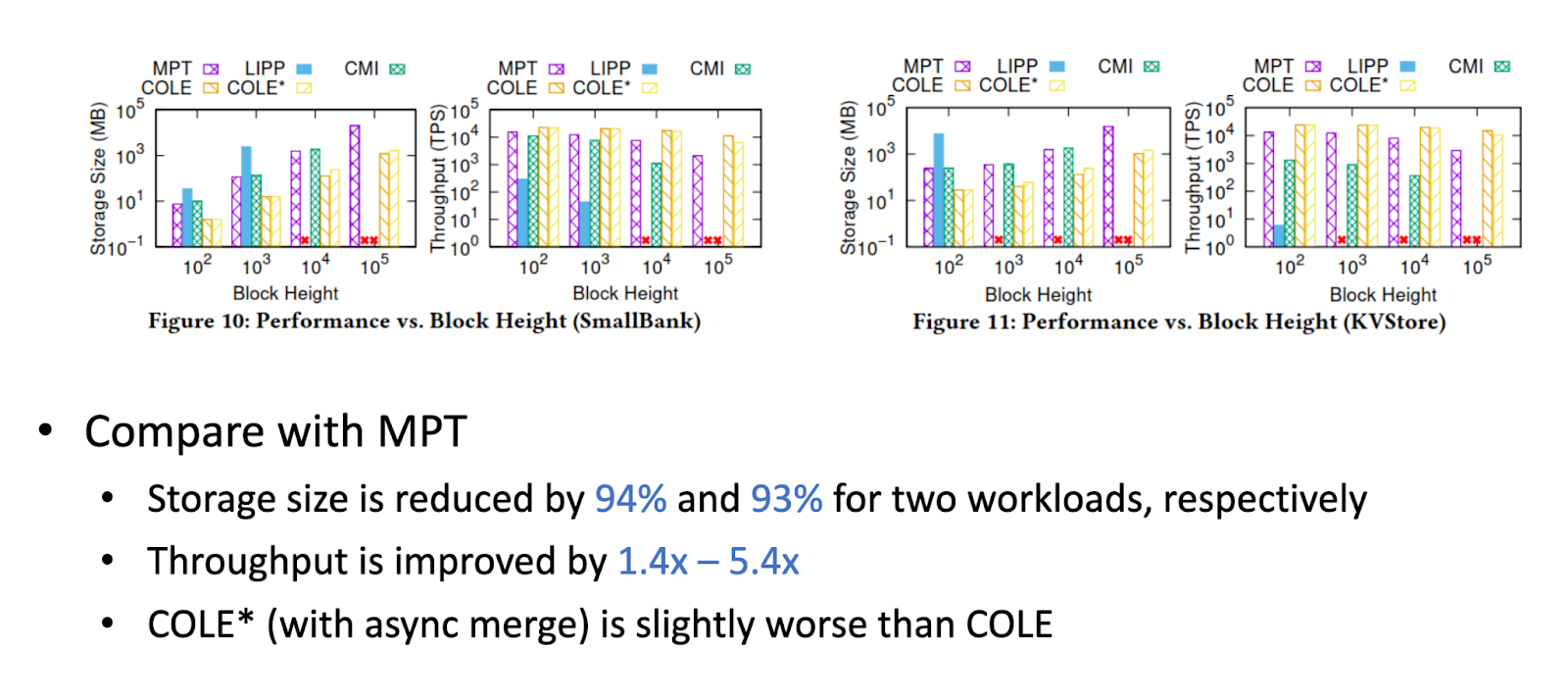
- Win for Space Utilization: Experiments in the COLE paper show ≈ 90% less disk than an MPT at the same block height because path duplication disappears.
- Win for Read: A historical lookup becomes a single seek + linear scan over a tiny slice.
Learned Position Models: Two-Page Point Reads
Learned Position Models, common in high-performance databases, are a groundbreaking innovation when applied to blockchain's unique data challenges. Eclipse is one of the first rollups investigating ML based learned position models, a breakthrough that could push read latencies below a millisecond and eliminate a long-standing data-access bottleneck.
Every run carries a tiny, ML-inferred piece-wise-linear model that predicts the byte offset of key (address, slot):
$$\text{offset}\approx m \cdot \text{key} + b,\qquad \lvert \text{error} \rvert \le \varepsilon$$
- Why it matters: The first probe lands within ε rows of the answer; a bounded scan finishes the job. Even when the ledger reaches petabyte scale, getAccount touches at most two pages—well under a millisecond on commodity SSDs.
The accuracy of these linear models is controlled by the epsilon parameter, which defines the maximum allowed prediction error. In the model generation process, when a new key-position pair cannot be added to the current linear segment within the epsilon bound, a new segment is created
Async LSM Merges: Throughput without Stalls
COLE-Star implements asynchronous merges through a dual-group system at both the in-memory and disk levels. The key insight is that while one group handles active writes, the other group can perform background merging operations concurrently.
Runs accumulate in tiered “levels.” Background threads merge older, overlapping runs into larger ones without blocking new writes (the cole-star trick):
- Why it matters: Tail-latency stays flat while the engine ingests million-TPS diffs. Operators size hardware for average load, not worst-case compaction spikes.
Levels represent different tiers of the storage hierarchy. Each level contains multiple runs, which are sorted collections of KV pairs stored on disk.
Rollback by Pointer Flip
The L2 rollbacks will be simple: “delete everything after slot F.”
Instead of rewriting data, we can keep a version map:
- Run-ID 17 — max_slot 12345678 — live
- Run-ID 18 — max_slot 12345700 — live
- Run-ID 19 — max_slot 12345730 — live
For example, on an L1 re-org that invalidates slot 12345712 we mark runs 18 and 19 “orphaned true” (i.e. live = false) and resume ingest. Disk I/O = zero; only metadata changes.
Putting the Pillars Together
- Fire-hose ingest → MB-Tree write-buffer + async merges.
- Slim disk → column runs, no path duplication.
- Instant rollback → version-map toggle.
- Sub-ms reads → learned models.
These pillars form the spine of the Fast RPC storage layer. The next section will walk through a concrete read and write flow to illustrate how they interact under a Gigascale load.
Read–Write Walk-Through at Gigascale
This section illustrates how an Eclipse-grade Fast RPC node can absorb writes, serve point reads and range scans (sequentially streaming all keys that share a prefix), and perform tip rollbacks—all while sustaining million-TPS throughput. The flow combines the column layout, learned index, async merges, and the rollback pointer that were laid out in Section, “Read-Write Walk Through”. Any numbers here are directional rather than measurements-based.

Write Path (one slot)
- In-memory buffer Each (addr, slot, value) diff is an O(1) append.
- Flush When the buffer fills up (~256k rows), it is frozen and dumped to an immutable Level-0 run:
- .s sorted key–value file
- .m learned model
- .h Merkle tree
- Async merge Background threads compact older runs; foreground ingest never stalls.
- Amortized cost ≈ 1 µs per write.
Point Read (getAccountWithProof)
- Locate run via the run index.
- Model jump
$$\text{offset}\approx m \cdot \text{key} + b,\qquad \lvert \text{error} \rvert \le \varepsilon$$
lands within ±ε rows.
- Scan ≤ ε rows → exact record (≤ 2 page reads).
- Return {value, Merkle branch, live-run roots}; append, where available, Celestia/Ethereum anchors if the caller wants an audit packet.
This could result in End-to-end latency < 1 ms on a single NVMe SSD.
Range Read (getProgramAccounts)
- Model jumps to the first key that matches the owner prefix.
- Sequentially stream rows until the prefix changes.
- NVMe bandwidth ⇒ millions of rows in a few-dozen ms.
Rollback (rare, tip-only)
- Receive L1 re-org / fraud-proof → new safe slot = F.
Flip live=false for every run with max_slot > F. - Resume ingest immediately; GC deletes orphaned runs after the dispute window.
- No files rewritten, only metadata toggled.
Why It Works
- Million-TPS ingest — in-memory MB-Tree + async merges; no write stalls.
- Controlled disk growth — column runs eliminate path duplication, saving ≈ 90 % vs. MPT.
- Sub-ms reads — learned model enables two-page look-ups.
- Instant rollbacks — metadata flip, not data rewrite.
This compact flow shows that a COLE-style store can keep abreast of the storage needs of Eclipse’s fast RPC nodes in lock-step with gigascale execution, while maintaining wallet-grade latency.
A Fast Storage Core Lifts the Entire Ecosystem
A lean, rollback-aware column store is more than an internal optimization; it is the keystone that lets every other layer of Eclipse move at giga-scale speed.
- Instant user experience: Sub-millisecond getAccount and getProgramAccounts keep wallets snappy, trading bots and DeFi apps reactive, and on-chain games smooth even when the ledger spans petabytes.
- Sustainable node economics: Column runs eliminate trie path duplication, so disk grows in line with real state, not with write frequency. Operators stay on commodity SSDs instead of enterprise arrays, enabling better node economics.
- Plug-and-play downstream tooling: RPC serves finality-tagged rows; Carbon pipelines, Kafka consumers, and bespoke indexers can subscribe immediately without re-parsing blobs or duplicating storage.
- Independent evolution of upper layers: With storage bottlenecks removed, transport protocols (gRPC, Turbine, etc.), indexing frameworks, light nodes and analytics stacks can iterate and scale independently instead of fighting the disk.
Therefore, solid storage unlocks the stack. It can turn Eclipse’s raw execution muscle into a data surface that developers, operators, and auditors can trust, and build on, at full speed.
Conclusions
Execution, sequencing, and storage constitute some of the most important and performance-critical elements of GSVM engineering. Borrowed from high-performance databases, learned position models become truly game-changing when repurposed for blockchain state. Eclipse is one of the first rollups to consider them, shrinking look-ups to sub-millisecond latency and eliminating a long-standing performance choke-point for on-chain applications. The COLE-inspired design sketched here shows a credible path to ingesting million-TPS, answering wallet queries in micro-seconds, and surviving the rare tip rollback, all on commodity SSDs. The pointer-flip rollback map still needs research, and the propagation bus adapter still needs code, but the direction is clear: column runs, learned offsets, async merges, minimal metadata for forks.
We are actively exploring this work and we welcome feedback, especially from teams running high-throughput high-integrity RPCs and indexers today. Solving storage first lets every other layer move faster, and Eclipse intends to keep the pace.
References
- Eclipse Performance Thesis
- COLE: the paper, slides, codebase and the talk.