In our previous article on Data Availability (DA) proofs, we discussed the complexities and solutions to design a DA bridge for high-throughput L2s. Since then, we went and implemented an actual optimistic ZK DA challenge system based on Celestia Blobstream. In this article, we will dive into the details of this system, its features and limitations.
💡In the rest of the article, we assume that you read the previous article. If you haven’t yet, go check it out!
Design
Where We Stopped Last Time
In the previous article, we proposed a multi-level DA commitment scheme for high-throughput L2s that we soberly named index blobs. The idea is that we need many blobs for every L2 block batch, and so instead of posting $N$ blobs on the Eclipse L1 smart contract, we first create a blob that lists (or serves as an index to) these N blobs, giving us the ability to post a single DA commitment per batch, regardless of its size.
When writing the article, we assumed that we would verify data availability for each blob in the index, meaning that we would need to verify $N+1$ Blobstream attestations. As a reminder, Blobstream is a Celestia block oracle on Ethereum that enables verifying data availability of blobs directly from Ethereum smart contracts.
The issue is that verifying this many attestations on-chain is prohibitive and forces the sequencer to post frequently to the L1. and would force us to write to the L1 too frequently, increasing sequencer costs. To avoid this scenario, we turned to RISC Zero’s Steel, a tool to turn on-chain view function calls into off-chain computations, resulting in a constant 300k gas cost for verifying a ZK proof on-chain independently of the complexity of the computations you perform off-chain.
We also assumed that this DA proof system would be embedded within the actual fraud proof system of Eclipse.
Design Update
It turns out that this design can be improved upon, in a number of ways. Our first observation is that DA proving should not necessarily be included with the fraud proof system. In the process of integrating Kailua as a fraud proof system, we realized that it assumes data availability and leaves DA proving to another component, the data availability challenge sub-system of OP Stack.
It turns out that this design has the advantage of modularity: fraud proofs are already complex on their own, therefore separating DA concerns is a good idea.
Furthermore, we can reduce the number of Blobstream attestations from $N+1$ to simply 1 by having the challenger identify the problematic blob before attempting to generate the DA proof. After all, the challenger will detect the unavailable blob when trying to fetch it from Celestia, the server will respond with an error indicating that the span sequence used to identify the blob is out of bounds.
Following this logic, we have 3 possible error cases:
- The unavailable blob is the index itself, so the index is irretrievable
- The index blob is available but malformed
- The unavailable blob is any blob inside the index.
It is trivial to determine the error case from a full node attempting to derive the state of the chain, so we just assume that this is done ahead of calling the DA challenge system. Here, the attentive reader will immediately ask “wait, but why do you need ZK proofs and Steel here then? Couldn’t you verify the Blobstream attestation for the challenged blob on-chain?”.
It is true that we could verify the Blobstream attestation for cheaper than a Groth16 ZK proof on-chain (90k gas vs. 300k). But we also need to deserialize the index blob, and this is hard to achieve on-chain. At high-throughput, we can theoretically have index blobs in the range of several MBs, while the maximum transaction size on Ethereum today is 128kB. In addition, writing this code in Rust with the help of serde and decompression libraries is significantly easier than doing the equivalent in Solidity.
It follows that ZK is the most sensible option. And if we have to pay the 300k gas fee anyway, we might as well perform all computations off-chain. Gas fees for optimistic DA challenges do not matter all that much as they should be more than covered by the sequencer bond, but we like efficiency. As it turns out (see below), we will need to verify more than one Blobstream attestation for the complete implementation.
TL;DR
To summarize, here are the features of the Eclipse ZK DA Challenge system:
- Optimistic DA challenge system, proves data unavailability
- Uses Celestia Blobstream to authenticate Celestia block
- Attestations verified off-chain with RISC Zero’s Steel
- Compatible with SP1 and RISC Zero implementations of Blobstream
- Constant, low costs:
- Sequencer: constant, 1 32-byte value to store on-chain (the span sequence of the index)
- Challenger: constant, 300k gas to verify the ZK proof + cost of proof generation, enabling cheaper and therefore broader participation to the protocol.
This system enables constant cost for the sequencer and the challenger, and infinite data scalability for Eclipse.
How the ZK challenger works
High-level flow
Let’s explore the code of the DA challenge guest! First, the general flow.
fn main() {
// Read the input from the guest environment.
let input: EthEvmInput = env::read();
let chain_spec: ChainSpec = env::read();
let blobstream_info: BlobstreamInfo = env::read();
let serialized_da_guest_data: Vec<u8> = env::read_frame();
// Converts the input into a `EvmEnv` for execution. The `with_chain_spec` method is used
// to specify the chain configuration. It checks that the state matches the state root in the
// header provided in the input.
let evm_env = input.into_env().with_chain_spec(&chain_spec);
let blobstream_address = blobstream_info.address;
match check_da_challenge(&evm_env, blobstream_info, serialized_da_guest_data) {
Ok(()) => panic!("the specified blob is available, DA challenge failed"),
Err(DaGuestError::Input(err)) => {
panic!("invalid input: {}", err)
}
Err(DaGuestError::Fraud(err)) => env::log(&format!("DA challenge success: {err}")),
}
// Commit the block hash and number used when deriving `view_call_env` to the journal.
let journal = Journal {
commitment: evm_env.into_commitment(),
blobstreamAddress: blobstream_address,
};
env::commit_slice(&journal.abi_encode());
}
We first extract inputs, which are read from stdin in RISC Zero guests. We have the following inputs:
- input: Data required to run Ethereum calls through Steel.
- chain_spec: Chain parameters such as the chain ID.
- blobstream_info: Address and implementation (R0 or SP1) of the Blobstream contract.
- serialized_da_guest_data: the actual input of the challenge. At this stage the data is still serialized, we later read into this struct:
#[derive(Debug, Serialize, Deserialize)]
pub struct DaChallengeGuestData {
pub index_blob: SpanSequence,
pub challenged_blob: SpanSequence,
pub index_blob_proof_data: Option<BlobProofData>,
pub block_proofs: BTreeMap<u64, BlobstreamAttestationAndRowProof>,
/// The attestation for the first Celestia block range covered by the Blobstream
/// contract. This field is used to determine the lower bound of Celestia block heights
/// on the current chain.
pub first_blobstream_attestation: BlobstreamAttestation,
}
This struct contains the following info:
- index_blob: The span sequence of the index blob.
- challenged_blob: The span sequence of the challenged blob. Can be any blob inside the index or the index blob itself.
- index_blob_proof_data: The shares and share proofs corresponding to the index blob. Optional because it cannot be retrieved if the index is unavailable.
- block_proofs: Blobstream attestations and additional Merkle proofs required to authenticate Celestia blocks and derive the corresponding data square sizes.
- first_blobstream_attestation: The attestation of the first Blobstream proof. We explain why this is needed in the block height validation section below.
We then create the Steel guest execution environment:
// Converts the input into a `EvmEnv` for execution. The `with_chain_spec` method is used
// to specify the chain configuration. It checks that the state matches the state root in the
// header provided in the input.
let evm_env = input.into_env().with_chain_spec(&chain_spec);
After processing the inputs, it’s time to check the validity of the DA challenge:
match check_da_challenge(&evm_env, blobstream_info, serialized_da_guest_data) {
Ok(()) => panic!("the specified blob is available, DA challenge failed"),
Err(DaGuestError::Input(err)) => {
panic!("invalid input: {}", err)
}
Err(DaGuestError::Fraud(err)) => env::log(&format!("DA challenge success: {err}")),
}
We have 3 possible outcomes here:
- The DA challenge is invalid, the index blob and all the blobs it points too are available.
- The challenger provided invalid inputs, which makes it impossible to process the challenge.
- The challenge is valid, the sequencer has performed DA fraud.
In the first two cases, we stop the execution of the guest immediately. If the challenge is valid, we proceed with the creation of the journal to record public outputs of the zkVM execution:
let journal = Journal {
commitment: evm_env.into_commitment(),
blobstreamAddress: blobstream_address,
};
env::commit_slice(&journal.abi_encode());
The journal is used later down the line as a public input for the prover.
Challenge Validation
Let’s now explore our check_da_challenge() function.
After some more input processing, we first verify all the Blobstream attestations passed to the guest:
// Verify the authenticity of all the provided block proofs.
for (block_height, block_proof) in &block_proofs {
assert_eq!(
*block_height, block_proof.blobstream_attestation.height,
"invalid block height"
);
verify_blobstream_attestation_and_row_proof(&blobstream_contract, block_proof);
}
This enables us to trust the data in these proofs later down the line. How are these proofs verified? Well, with Steel obviously! We use our Steel EVM execution environment to instantiate a Contract instance representing the Blobstream contract. With Steel, we can call the IDAOracle::verifyAttestation method similarly to how we would on-chain:
fn verify_blobstream_attestation(
blobstream_contract: &Contract<&EvmEnv<StateDb, EthBlockHeader, Commitment>>,
blobstream_attestation: &BlobstreamAttestation,
) {
let formatted_proof = BinaryMerkleProof::from(blobstream_attestation.proof.clone());
let blobstream_call = IDAOracle::verifyAttestationCall {
_tupleRootNonce: U256::from(blobstream_attestation.nonce),
_tuple: DataRootTuple {
height: U256::from(blobstream_attestation.height),
dataRoot: B256::from_slice(&blobstream_attestation.data_root),
},
_proof: formatted_proof,
};
// `verifyAttestation()` returns nothing, discard the return value
let _blobstream_return = blobstream_contract.call_builder(&blobstream_call).call();
}
We then check the challenge type: if we’re challenging the index blob, we check it immediately by verifying that its block height and data square indexes are within bounds:
// If the index blob is the missing blob, verify exclusion first.
if challenged_blob == index_blob {
// Verify that the index blob is excluded
check_block_height_bounds(
index_blob,
&blobstream_contract,
blobstream_impl,
first_blobstream_attestation,
)?;
return verify_span_sequence_inclusion(
&index_blob,
&block_proofs[&index_blob.height].row_proof,
);
}
Pretty simple. But what if we are challenging a blob inside the index instead? First, we need to deserialize the index. The challenger provides all the data as input, but how can we trust it?
That’s the role of share proofs: the caller provides an inclusion proof for all the Celestia shares it provides. This guarantees that we are processing the data associated to the index blob.
// To go any further, the index blob data must be present.
let index_blob_data = index_blob_data.ok_or(InputError::MissingIndexBlobData)?;
// Verify the share proofs of the index blob
verify_share_proofs(
&index_blob,
&block_proofs[&index_blob.height].blobstream_attestation,
&index_blob_data,
)?;
// ...
let index = BlobIndex::reconstruct_from_raw(index_blob_data.shares(), app_version)?;
If the deserialization fails here, it means that the index blob data is invalid, i.e. that the challenge is valid. But assuming that it succeeds, we now only need to search the index to find the challenged blob and perform the same checks as above:
// Iterate over the blobs in the index and check if they're the missing blob.
for blob_commitment in index.blobs {
if challenged_blob == blob_commitment {
check_block_height_bounds(
challenged_blob,
&blobstream_contract,
blobstream_impl,
first_blobstream_attestation,
)?;
return verify_span_sequence_inclusion(
&blob_commitment,
&block_proofs[&blob_commitment.height].row_proof,
);
}
}
Err(InputError::ChallengedBlobNotInIndex.into())
Of course, the challenge fails is the challenged blob is not found. And that’s it! With this relatively simple flow, we covered all 3 possible challenge types: unavailable or malformed index and unavailable blob inside the index.
Implementation Challenges
Things are sadly never as simple as they seem. Let’s discuss a few issues that we had to solve during development.
Block Height Validation
As a reminder, Celestia span sequences are defined as a tuple of 3 elements that uniquely identify a blob:
pub struct SpanSequence {
/// Celestia block height.
pub height: u64,
/// Index of the first share of the blob in the block's
/// original data square (ODS).
pub start: u32,
/// Number of shares that make up the blob, excluding parity shares.
pub size: u32,
}
We already talked at length about proving data (un)availability based on the blob’s position in the data square in the previous article, but we only briefly touched block height validation in the previous section. What if the sequencer just tells you that the data is in a Celestia block that will only be produced in a thousand years? To avoid this situation, we need to determine the range of Celestia blocks covered by the instance of Blobstream. This is trickier than it sounds: Blobstream deployments usually do not start at the genesis block, and there is no generic method to determine the current latest block height.
To determine the start of the block range, we use a property of all Blobstream implementations, the proof nonce. By fetching the Blobstream attestation corresponding to the proof nonce, we can easily derive the first block submitted to the current Blobstream instance. This does mean verifying an additional Blobstream attestation to authenticate the block height.
💡 To index or not to index?
Finding the first Blobstream attestation is like finding a needle in a haystack. Without additional information, you’d first need to find the block at which the Blobstream instance was created, then index from there. It turns out that this is nontrivial and may require the use of archival nodes.
You could hardcode the contract’s creation block in the ZK guest program. But if you decide to hardcode some values, why not hardcode the entire Blobstream attestation?
This is what we ended up doing for the mainnet and Sepolia implementations of Blobstream. As the proof is verified in ZK anyway, it is just simpler to do away with the indexing entirely.
pub async fn get_first_data_commitment_event<T: Clone + Transport, P: Provider<T, Ethereum>>(
chain_id: ChainId,
blobstream_address: Address,
provider: &P,
) -> Result<SP1BlobstreamDataCommitmentStored, anyhow::Error> {
let data_commitment = match chain_id {
SEPOLIA_CHAIN_ID => SP1BlobstreamDataCommitmentStored {
proof_nonce: U256::from(1u64),
start_block: 1_560_501,
end_block: 1_560_600,
data_commitment: B256::from_str(
"60cd79d32f2fb32ba0086c2d0f8e00d54364fa93715a4f6b28ed4080ef47f0eb",
)?,
},
MAINNET_CHAIN_ID => SP1BlobstreamDataCommitmentStored {
proof_nonce: U256::from(1u64),
start_block: 1_605_975,
end_block: 1_606_500,
data_commitment: B256::from_str(
"e0f22e19a558e8da31aa8ee05f737a3ec2a55f92dc6093f34650c69f4cbd53be",
)?,
},
_ => {
let blobstream_contract = SP1BlobstreamInstance::new(blobstream_address, provider);
find_first_data_commitment_event(blobstream_contract, 100_000).await?
}
};
Ok(data_commitment)
}
For the maximum height currently covered, there is no generic method in the IDAOracle interface of Blobstream, but the SP1 and RISC Zero implementations of Blobstream provide two similar methods: latestBlock() and latestHeight(). As one can imagine, these two methods provide similar functionality, the only difference being that the SP1 Blobstream method is range-exclusive, while RISC Zero’s Blobstream0’s is range-inclusive:
fn get_current_blobstream_height(
blobstream_contract: &Contract<&EvmEnv<StateDb, EthBlockHeader, Commitment>>,
blobstream_impl: BlobstreamImpl,
) -> u64 {
match blobstream_impl {
BlobstreamImpl::Sp1 => {
let height_call = SP1Blobstream::latestBlockCall {};
blobstream_contract.call_builder(&height_call).call()._0 - 1
}
BlobstreamImpl::R0 => {
let height_call = Blobstream0::latestHeightCall {};
blobstream_contract.call_builder(&height_call).call()._0
}
}
}
Combining these two solutions solves our block range validation issue.
Security Concerns
Timing Issues - Working Around Steel History
A great feature of RISC Zero’s Steel is that it can be used to prove statements at any Ethereum block after the Cancun upgrade. It does pose the problem that anyone can prove that any Celestia block height is out of range by simply placing the Steel execution block before the corresponding Blobstream update. Meaning, we need a mechanism to enforce that rewinding time for the off-chain program does not enable creating valid DA challenge proofs.
While relatively trivial to implement (you only need to attach the currrent block height to the batch metadata on L1), this forces developers to customize the proof system to verify that the proof is not proving an invalid DA challenge on a block older than the blob.
Liveness
As we rely on Blobstream, the immediate question is what are the off-chain components that we end up depending on? From the previous point, we see that block batches must not be posted to L1 before the corresponding Celestia blocks are covered by the Blobstream implementation. Blobstream is an oracle by nature, meaning that it represents the current state of the Celestia chain on Ethereum. It needs to be updated by an off-chain component to reflect the state of Celestia.
SP1-Blobstream, the current reference implementation, relies on ZK proofs for updates. An off-chain component first has to generate a ZK proof that the new Celestia blocks are indeed valid, then updates the Blobstream state. At the time of writing, the reference implementation is updated every hour. But what if it stops updating?
.png)
We see in this diagram that we rely on at least one centralized system:
- The Blobstream relayer is a single point of failure, there is no decentralized Blobstream relayer currently in production
- If the relayer relies on a centralized prover service, proof generation can also be censored.
Additionally, SP1-Blobstream supports both relayer authentication and freezing of updates, meaning that in the case of a failure it becomes impossible to update the smart contract. This is not the case for Blobstream0, which is completely permissionless.
So, if we rely on the reference implementation, we see that:
- We have a worst-case of one hour of latency before being able to post to L1. This delay is programmable and can theoretically increase.
- If the relayer goes down, it may be impossible to supplement it by an emergency instance if relayer authentication is enforced.
- Even if authentication is disabled, it may be impossible to update the contract if it is frozen.
Using Blobstream0, the freezing and authentication issues disappear, but we are still subject to liveness issues if the service is run by a third-party.
For Eclipse mainnet, the only sensible solution is therefore to run our own instance of Blobstream.
Performance
This wouldn’t be an article on Eclipse without talking about performance. Performance does not really matter for optimistic challenges, but it does have an impact on cost and therefore on the decentralization of the challenge system. We want anyone to be able to detect data unavailability, submit a challenge and provide a corresponding proof.
The following numbers are achieved on a laptop with an Intel Ultra 7 155H CPU (16/32 cores) and 96GB of RAM.
A typical run of the ZK guest program takes between 200ms and 500ms, depending on the complexity of the task. From there, creating the proof on a specialized proving network (RISC Zero’s Bonsai) takes around 40 seconds. Creating the proof locally can also be done, and takes around 20 minutes. This essentially means that anyone can generate a valid proof with our DA challenge system, without even relying on a prover network.
This is already a great result, but can this be improved? Let’s take a look at the flame graph of the guest program.
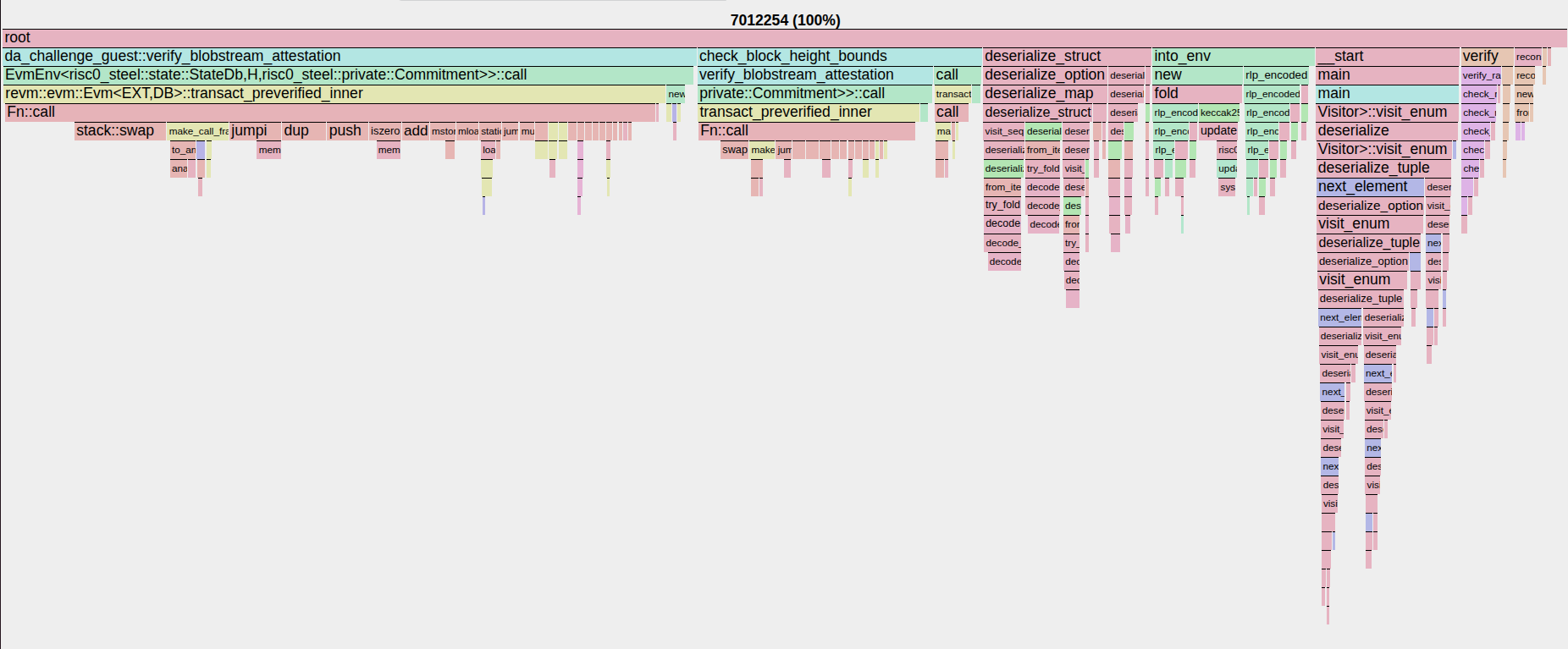
We see that most of the time is spent verifying the Blobstream attestations with Steel. This checks out: Steel has to verify state proofs for every state variable it reads and emulates the EVM to run the Blobstream smart contract code.
This parameter is out of control, and the flame graph clearly shows that optimizing other parts of the guest would only result in minimal improvements. We’ll have to rely on future prover improvements to drive the proving time further down, such as the future RISC Zero v3 update using the Binius proof system.
Conclusion
The new Eclipse ZK DA challenge system enables verifiable Celestia DA commitments on Ethereum without sacrificing on performance and cost-effectiveness. This demonstrates our commitment towards L2 stage 1 and beyond. By open-sourcing this component, we hope to show our love of open-source and help improve the security of all L2s that use Celestia.